This website contains animated figures both from the main article and the supplementary material of our paper:
Interpreting Video Features: a Comparison of 3D Convolutional Networks and Convolutional LSTM Networks
Joonatan Mänttäri*, Sofia Broomé*, John Folkesson, Hedvig Kjellström. *Joint first authorship
ACCV 2020, 15th Asian Conference on Computer Vision, to appear.
@InProceedings{ManttariBroome_2020_Interpreting_Video_Features,
title={Interpreting Video Features: a Comparison of 3D Convolutional Networks and Convolutional LSTM Networks},
author={Joonatan M\"antt\"ari* and Sofia Broom\'e* and John Folkesson and Hedvig Kjellstr\"om},
year={2020},
booktitle={Computer Vision - ACCV 2020, 15th Asian Conference on Computer Vision, to appear. (*Joint first authors)},
month = {December}
}
The hyperparameters used in the work can be found at the bottom of the page. If you find the article useful for your research, please cite it.
Abstract: A number of techniques for interpretability have been presented for deep learning in computer vision, typically with the goal of understanding what the networks have actually learned underneath a given classification decision. However, interpretability for deep video architectures is still in its infancy and we do not yet have a clear concept of how to decode spatiotemporal features. In this paper, we present a study comparing how 3D convolutional networks and convolutional LSTM networks learn features across temporally dependent frames. This is the first comparison of two video models that both convolve to learn spatial features but that have principally different methods of modeling time. Additionally, we extend the concept of meaningful perturbation introduced by Fong et al. to the temporal dimension to search for the most meaningful part of a sequence for a classification decision.
Results samples from main article
| Class | Scores I3D | I3D | CLSTM | Scores CLSTM |
|---|---|---|---|---|
| Moving something and something away from each other | OS: 0.994 FS: 0.083 RS: 0.856 |
 |
 |
0.312 0.186 0.125 |
| Moving something and something closer to each other Predicted: 38: Moving something and something so they collide with each other 135: Something falling like a rock |
OS: 0.547 FS: 0.028 RS: 0.053 P: 38 |
 |
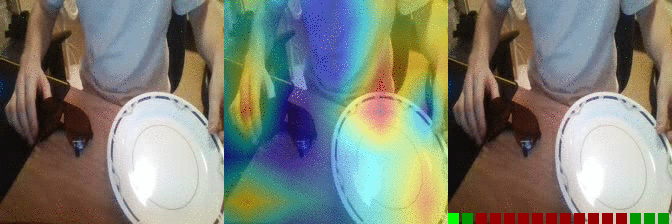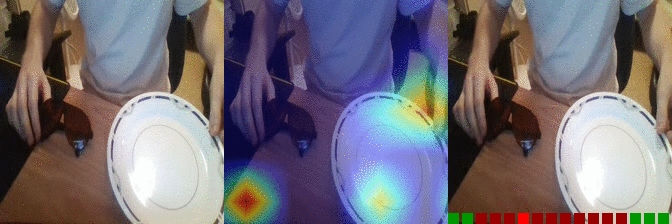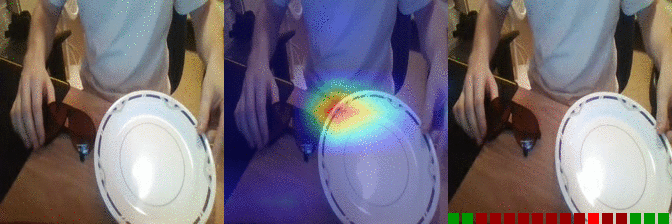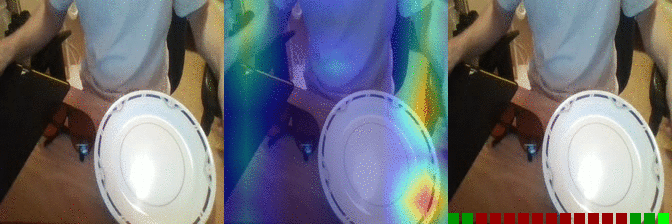 |
0.257 0.079 0.122 P: 135 |
| Moving something and something so they pass each other | OS: 0.999 FS: 0.002 RS: 0.414 |
 |
 |
0.788 0.392 0.537 |
| Moving something up | OS: 0.804 FS: 0.016 RS: 0.667 |
 |
 |
0.546 0.121 0.764 |
| Moving something up Predicted: 146: Taking one of many similar things on the table 100: Pushing something so that it slightly moves |
OS: 0.685 FS: 0.003 RS: 0.048 CS: 0.001 P: 146 |
 |
 |
0.221 0.182 0.350 CS: 0.005 P: 100 |
| Pretending to take something from somewhere Predicted: 27: Lifting something up completely without letting it drop down |
OS: 0.284 FS: 0.003 RS: 0.006 |
 |
 |
0.600 0.167 0.088 CS: 0.004 P: 27 |
| Turning the camera downwards while filming something | OS: 1.000 FS: 0.001 RS: 0.011 |
 |
 |
0.158 0.063 0.093 |
| Turning the camera upwards while filming something | OS: 0.990 FS: 0.001 RS: 0.000 |
 |
 |
0.806 0.177 0.181 |
Further Examples of Spatio-temporal Features:
Below, we present results for 22 additional randomly selected sequences (two from each class) from the Something-something dataset. As mentioned in the main article, we selected eleven classes where the two models had comparable performance, both poor and strong. The four classes not appearing above are (I3D F1-score/C-LSTM F1 score): moving something and something so they collide with each other (0.16/0.03), burying something in something (0.1/0.06), turning the camera left while filming something (0.94/0.79) and turning the camera right while filming something (0.91/0.8).
| Class | Mask Losses I3D | I3D | CLSTM | Mask Losses CLSTM |
|---|---|---|---|---|
| Turning the camera downwards while filming something | OS: 1.000 FS: 0.015 RS: 0.003 |
 |
 |
0.373 0.547 0.224 |
| Turning the camera downwards while filming something | OS: 0.999 FS: 0.000 RS: 0.000 |
 |
 |
0.921 0.238 0.460 |
| Turning the camera left while filming something | OS: 0.997 FS: 0.012 RS: 0.014 |
 |
 |
0.988 0.183 0.105 |
| Turning the camera left while filming something | OS: 0.999 FS: 0.001 RS: 0.451 |
 |
 |
OS: 0.985 FS: 0.229 RS: 0.094 |
| Turning the camera right while filming something Predicted: 157: Tilting something with something on it until it falls off |
OS: .940 FS: 0.106 RS: 0.017 |
 |
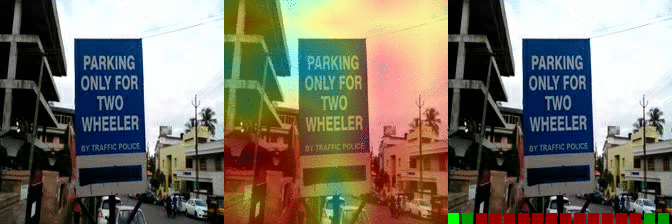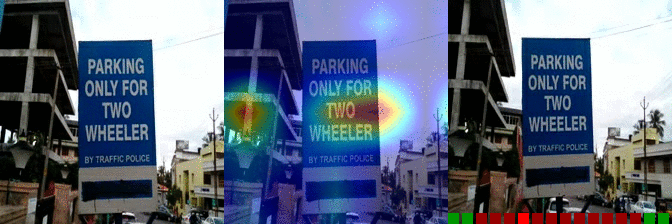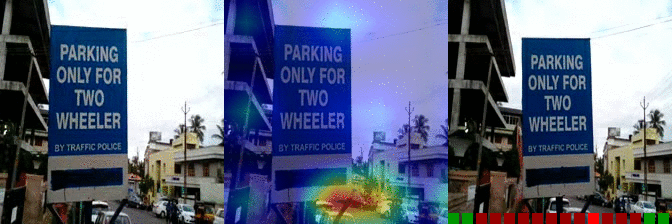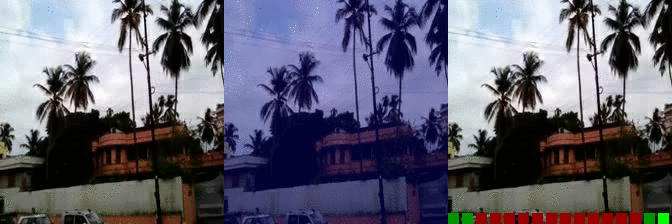 |
OS: 0.192 FS: 0.261 RS: 0.140 CS: 0.103 P: 157 |
| Turning the camera right while filming something | OS: .947 FS: 0.005 RS: 0.188 |
 |
 |
OS: 0.708 FS: 0.093 RS: 0.119 |
| Turning the camera upwards while filming something | OS: 0.999 FS: 0.001 RS: 0.002 |
 |
 |
OS: 0.687 FS: 0.205 RS: 0.149 |
| Turning the camera upwards while filming something | OS: 0.997 FS: 0.002 RS: 0.064 |
 |
 |
OS: 0.689 FS: 0.108 RS: 0.129 |
| Moving something and something away from each other Predicted: 121: Removing something, revealing something behind |
OS: 0.917 FS: 0.058 RS: 0.071 |
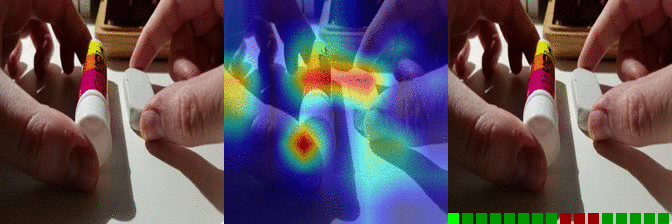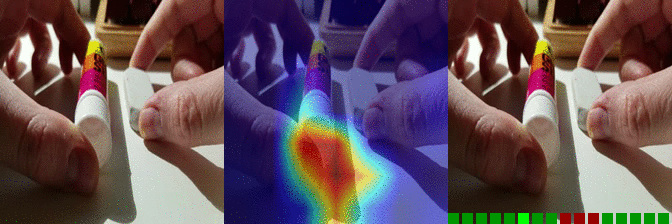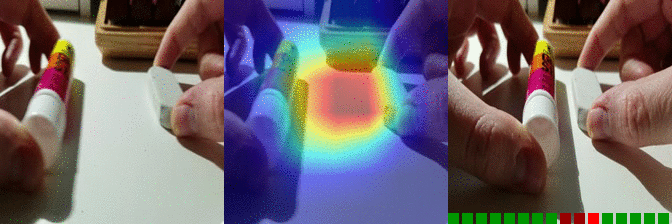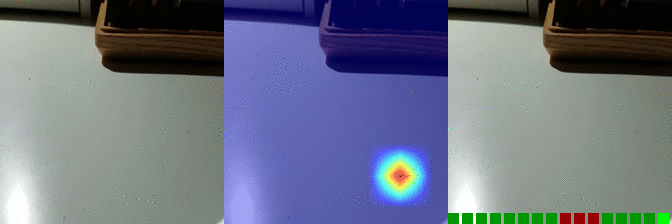 |
 |
OS: 0.297 FS: 0.155 RS: 0.294 CS: 0.085 P:121 |
| Moving something and something away from each other Predicted: 130: Showing that something is inside something |
OS: 0.991 FS: 0.022 RS: 0.956 |
 |
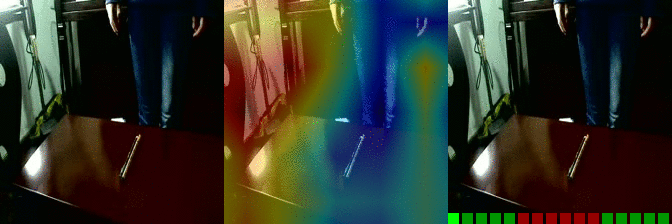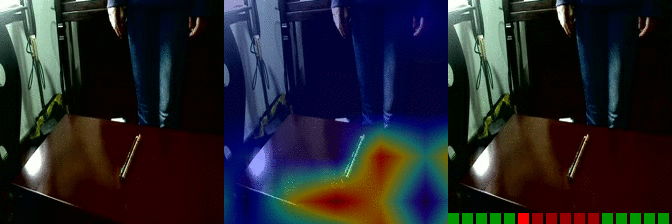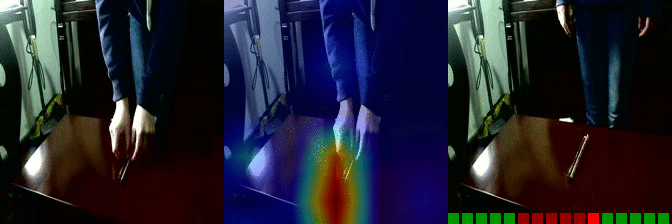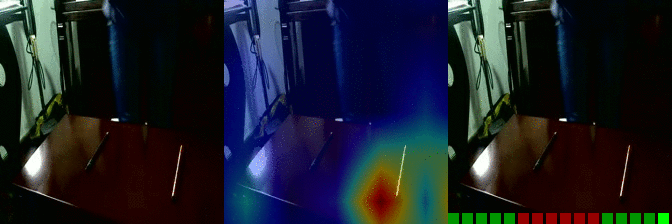 |
OS: 0.259 FS: 0.081 RS: 0.146 CS: 0.008 P: 130 |
| Moving something and something closer to each other Predicted: 173: Wiping something off of something 100: Pushing something so that it slightly moves |
OS: 0.273 FS: 0.004 RS: 0.245 CS: 0.001 P:173 |
 |
 |
OS: 0.1230 FS: 0.375 RS: 0.200 CS: 0.012 P: 100 |
| Moving something and something closer to each other | OS: 0.932 FS: 0.002 RS: 0.007 |
 |
 |
OS: 0.453 FS: 0.063 RS: 0.198 |
| Moving something and something so they collide with each other | OS: 0.686 FS: 0.003 RS: 0.000 |
 |
 |
OS: 0.620 FS: 0.145 RS: 0.129 |
| Moving something and something so they collide with each other Predicted: 37: Moving something and something closer to each other |
OS: 0.810 FS: 0.055 RS: 0.419 |
 |
 |
OS: 0.333 FS: 0.119 RS: 0.276 CS: 0.030 P:37 |
| Moving something and something so they so they pass each other | OS: 0.997 FS: 0.007 RS: 0.974 |
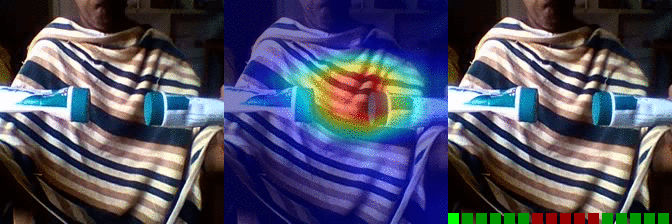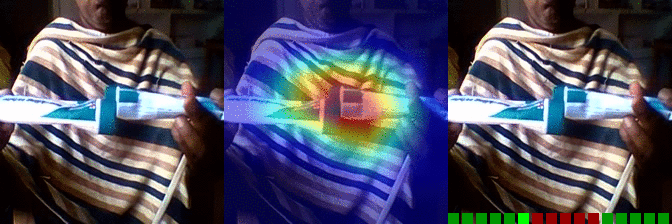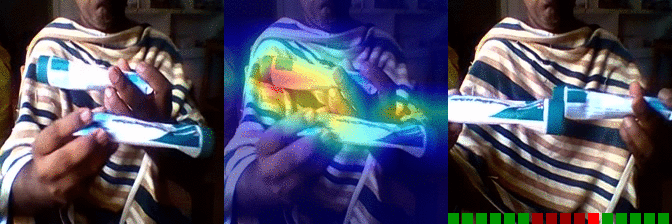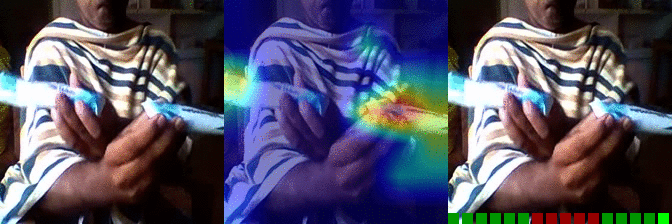 |
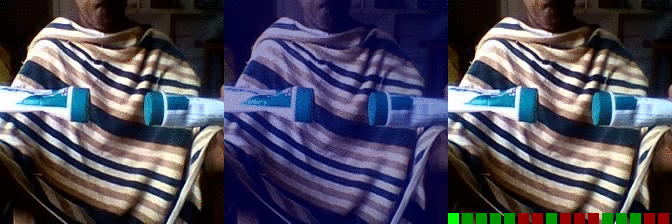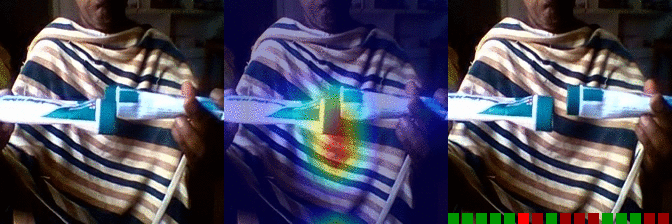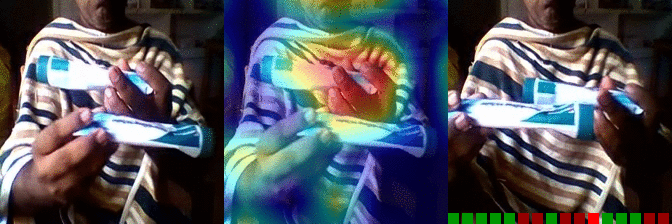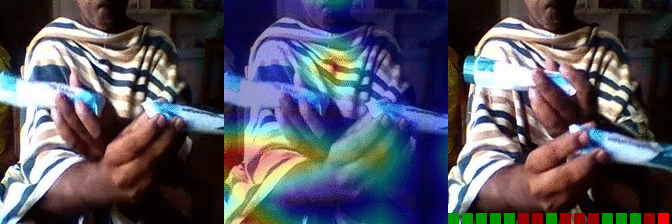 |
OS: 0.737 FS: 0.490 RS: 0.140 |
| Moving something and something so they so they pass each other Predicted: 37: Moving something and something closer to each other |
OS: 0.694 FS: 0.010 RS: 0.003 CS: 0.273 P: 37 |
 |
 |
OS: 0.813 FS: 0.227 RS: 0.830 CS: 0.142 P: 37 |
| Burying something in something Predicted: 145: Taking one of many similar things on the table 157: Tilting something with something on it until it falls off |
OS: 0.619 FS: 0.010 RS: 0.216 CS: 0.020 P: 145 |
 |
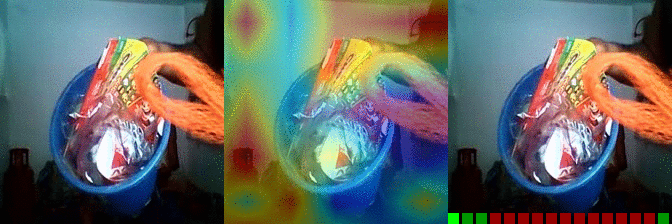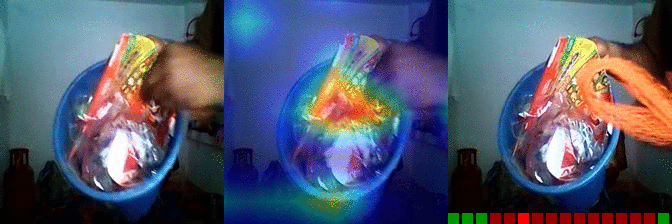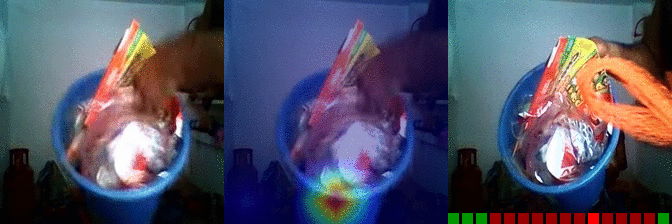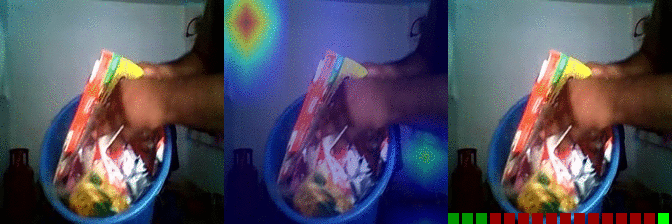 |
OS: 0.013 FS: 0.079 RS: 0.262 CS: 0.001 P: 157 |
| Burying something in something Predicted: 106: Putting something into something 5: Closing something |
OS: 0.177 FS: 0.007 RS: 0.130 CS: 0.027 P: 106 |
 |
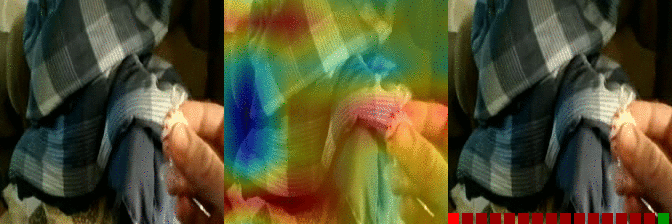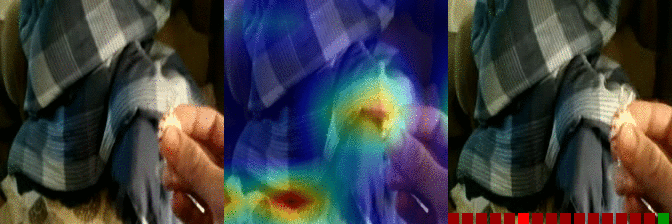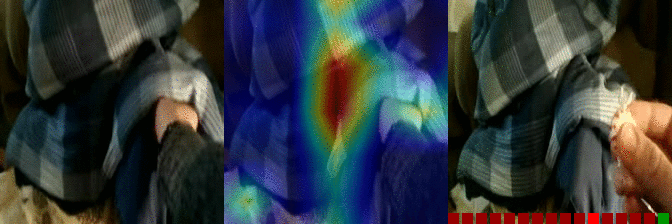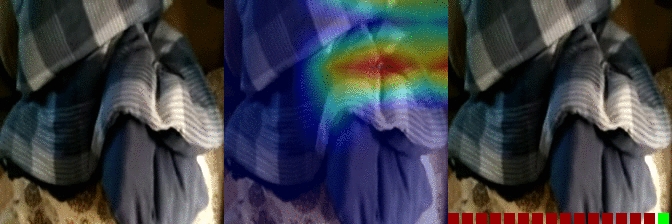 |
OS: 0.112 FS: 0.147 0.327 CS: 0.002 P: 5 |
| Moving something up Predicted: 27: Lifting something up completely without letting it drop down 100: Pushing something so that it slightly moves |
OS: 0.848 FS: 0.065 RS: 0.380 CS: 0.003 P: 27 |
 |
 |
OS: 0.229 FS: 0.102 RS: 0.269 CS: 0.003 P: 100 |
| Moving something up Predicted: 100: Pushing something so that it slightly moves |
OS: 0.755 FS: 0.012 RS: 0.032 |
 |
 |
OS: 0.230 FS: 0.146 RS: 0.200 CS: 0.003 P: 100 |
| Pretending to take something from somewhere Predicted: 160: Touching (without moving) part of something |
OS: 0.810 FS: 0.019 RS: 0.682 CS: 0.000 P: 160 |
 |
 |
OS: 0.179 FS: 0.073 RS: 0.162 CS: 0.004 P: 160 |
| Pretending to take something from somewhere Predicted: 145: Stuffing something into something 160: Touching (without moving) part of something |
OS: 0.325 FS: 0.012 RS: 0.126 CS: 0.047 P: 145 |
 |
 |
OS: 0.418 FS: 0.062 RS: 0.266 CS: 0.011 P: 160 |
Hyperparameters for model training
| Model (dataset) | Dropout Rate | Weight Decay | Optimizer | Epochs | Momentum |
|---|---|---|---|---|---|
| I3D (smth-smth) | 0.5 | 0 | ADAM | 13 | - |
| I3D (KTH) | 0.7 | 5E-5 | ADAM | 30 | - |
| C-LSTM (smth-smth) | 0 | 0 | SGD | 105 | 0.2 |
| C-LSTM (KTH) | 0.5 | 1E-4 | SGD | 21 | 0.2 |
Hyperparameters for temporal mask inference
| Dataset | Lambda1 | Lambda2 | Beta | Optmizer | Iterations | Learning Rate |
|---|---|---|---|---|---|---|
| Smth-Smth | 0.01 | 0.02 | 3 | ADAM | 300 | 0.001 |
| KTH | 0.02 | 0.04 | 3 | ADAM | 300 | 0.001 |